

Originalmente chamado Knapsack Problem, o Problema da Mochila é clássico para pessoas estudiosas da matemática e suas engenharias. Sua forma mais comum é: temos uma mochila com capacidade máxima de peso e vários itens inteiros com pesos e preços diferentes, então qual o maior lucro podemos guardar sem exceder o limite de peso da mochila? Especificamente é o 0/1 Knapsack Problem, pois os itens são indivisíveis, isto é, cada item entra na mochila inteiro (1) ou é excluído (0), sem meio termo.
Não é um exercício puramente teórico, possui varias aplicações práticas para otimização de recursos do mundo real. Resolveremos com a linguagem funcional Elixir. E, mais à frente, comentarei sobre como entreguei uma variação deste algoritmo em um aplicativo que contribuo.
A interface de nossa função: inputs e output 🤖
Para fins didáticos, começarei expondo a interface.
Será uma função zero_one_knapsack, cujo primeiro argumento é uma lista de itens (cada item sendo um mapa com chaves peso weight e preço profit), o segundo argumento será a capacidade máxima da mochila, enquanto o retorno será o preço máximo possível de ter sido armazenado.
Os números são todos inteiros, ainda para fins didáticos.
@spec! zero_one_knapsack(
[%{profit: integer(), weight: integer()}],
integer()
) :: integer()
TDD: casos de teste básicos do 0/1 knapsack problem
Casos básico: coube um item
Busquei na Internet alguns casos simples para ir me orientando se acertei o “alvo” ou não durante a programação. Assim os escrevi no framework nativo de testes automatizados ExUnit da Elixir. Vejamos rapidinho o código e explicarei imediatamente depois:
test "W = 4, profit[] = {1, 2, 3}, weight[] = {4, 5, 1}" do
objects = [
%{profit: 1, weight: 4},
%{profit: 2, weight: 5},
%{profit: 3, weight: 1}
]
weight_limit = 4
assert zero_one_knapsack(objects, weight_limit) == 3
end
Usarei como unidades arbitrárias “kg” e “$” apenas por verossimilhança, mas poderiam ser quaisquer outras.
Vejamos, no primeiro teste, a capacidade da mochila é de 4kg, e os itens possíveis são o primeiro $1 pesando 4kg, o segundo $2 pesando 5kg e o terceiro $3 pesando 1kg. O resultado é que o melhor lucro a ser armazenado é $3.
Por quê?
Dentre os itens possíveis, já temos que o segundo item jamais será considerado pois seu peso 5kg excede a capacidade da mochila de 4kg.
Sobram o primeiro e terceiro, então optaremos por guardar o terceiro por ter maior lucro $3. Pondo este terceiro item de $3 pesando 1kg, a mochila ficará com 3kg de capacidade, pois é a capacidade anterior menos o peso que armazenamos.
Repetiremos o algoritmo. Porém agora só sobrou o primeiro item e a capacidade restante da mochila é de 3kg. O tal primeiro item tem peso 4kg que excede a mochila, então essa nossa filtragem inicial o exclui.
Não restam mais itens a se considerar depois disso. E é quando decidimos por parar.
Ao fim, só conseguimos armazenar o segundo item de $3 e 1kg. Logo, o máximo de valor armazenado foi $3.
Caso estranho, mas ainda básico: nada coube
Já o outro exemplo resultou em 0, não conseguiu armazenar nada, pois todos os itens possíveis excediam a capacidade da mochila:
test "W = 3, profit[] = {1, 2, 3}, weight[] = {4, 5, 6}" do
objects = [
%{profit: 1, weight: 4},
%{profit: 2, weight: 5},
%{profit: 3, weight: 6}
]
weight_limit = 3
assert zero_one_knapsack(objects, weight_limit) == 0
end
Caso um pouco mais complicado: couberam dois itens
Por fim, um exemplo mais complicado, em que dois itens couberam na mochila:
test "W = 50, profit[] = {60, 100, 120}, weight[] = {10, 20, 30}" do
objects = [
%{profit: 60, weight: 10},
%{profit: 100, weight: 20},
%{profit: 120, weight: 30}
]
weight_limit = 50
assert zero_one_knapsack(objects, weight_limit) == 220
end
O comportamento não teve nada de diferente, mas este exemplo deixa mais óbvio a necessidade de repetição: a gente não para de tomar decisões só porque um item coube, mas porque as possibilidades restantes acabaram.
Inicialmente todos os itens eram possíveis pelo peso, então entrou primeiro o de maior lucro $120 pesando 30kg. O novo limite desceu de 50 para 20kg após isso. Os outros dois continuavam possíveis, então entrou o de maior lucro dentre eles que era o de $100 pesando 20kg, fazendo o limite descer de 20 para 0kg. E o item restante de 10kg já excedia este limite e não podia ser mais considerado. Ao fim, o somatório dos itens armazenados deu $120 + $100 = $220.
O algoritmo da mochila 🎒
Passo a passo
Lendo atentamente o comportamento descrito na justificativa dos testes acima, já temos o nosso algoritmo: dada a capacidade atual, filtramos os itens que cabem e dentre estes guardaremos o de maior valor, depois usamos os itens restantes e a capacidade restante para repetirmos as mesmas tomadas de decisão. Segue um fluxograma mais detalhado:
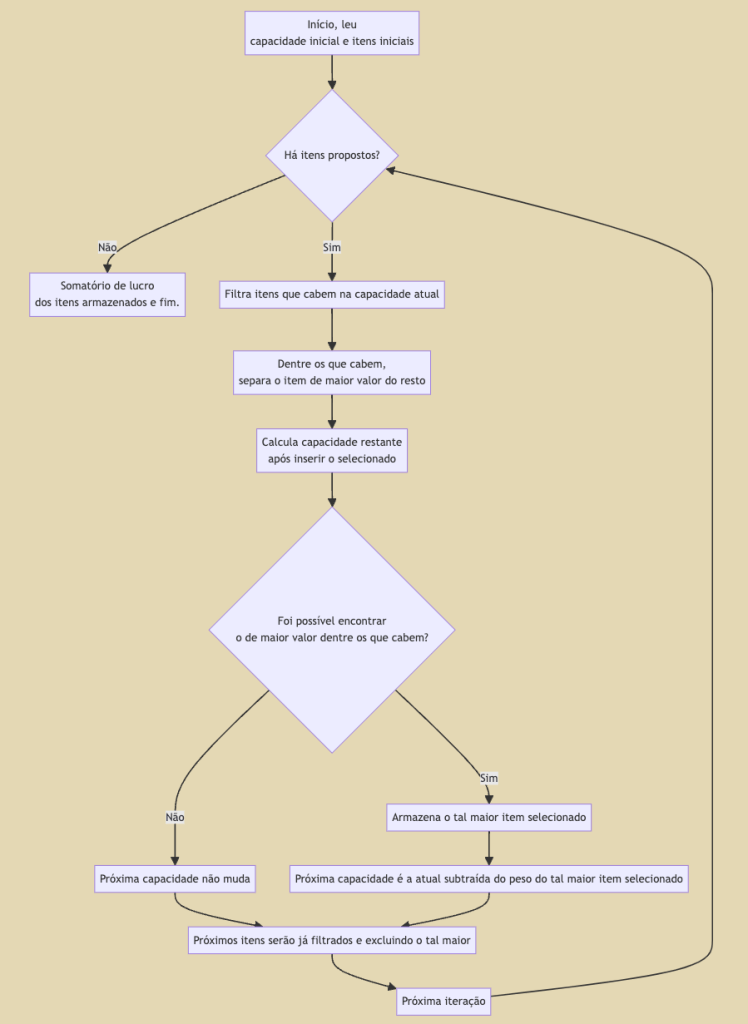
Refletiremos um pouco sobre esse algoritmo acima.
Uma primeira análise é que esse algoritmo é “guloso” (greedy), porque decisões são tomadas usando apenas o que há disponível naquele passo da repetição, decisões do passado são imutáveis e as do futuro são ignoradas.
P ou NP?
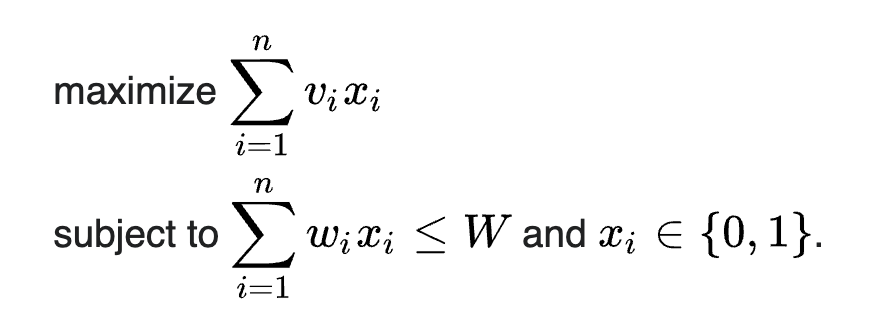
A fórmula acima é a definição mais formal do problema. Podemos encontrar a melhor resposta por força bruta em tempo não polinomial, isto é, pode até demorar mais do que o tempo de existência humana. Enquanto é bem fácil checar rapidamente se é válida ou não através do somatório acima, ou seja, em tempo polinomial.
O que quero dizer é que estamos diante de um problema NP-completo. O impacto disso na prática é que é bem mais fácil e rápido computacionalmente validar a solução do que chegar até a solução perfeita. A melhor resposta sempre será conseguida somente via força bruta testando todas as combinações, mas nosso algoritmo guloso encontrará soluções muito boas pra maior parte dos casos.
Resolver problemas assim com maior eficiência está dentre os grandes desafios da humanidade.
Implementando o Knapsack em Elixir
Agora, seguiremos para a implementação. Para quem está familiarizado com linguagens funcionais, não temos loops procedurais como for e while, então usaremos funções de alta ordem (high-order functions ou HOF) como map e filter para que funções usem outras funções em prol de transformação de valores. E também usaremos recursão. 👽
Começaremos do maior nível de abstração. A função zero_one_knapsack anteriormente definida:
def zero_one_knapsack(items, weight_limit) do
keep_packing(items, weight_limit)
|> Enum.map(& &1.profit)
|> Enum.sum()
end
O código acima assume que haverá uma função keep_packing que retornará uma lista de todos os itens empacotados, e em seguida para cada item empacotado a gente pega o lucro e os soma. Em outras palavras, essa função integra a entrada, orquestra funções menores e assegura a saída, pouca lógica propriamente dita.
Dei o nome de “continue empacotando” para aquela função apenas para dar uma noção de “movimento” a ela, pois é esperado que seja recursiva, então deixar claro usando a palavra no gerúndio (empacotando) é um hábito meu.
Agora, aos detalhes de implementação, a keep_packing a seguir:
defp keep_packing(items, weight_limit) do
{biggest_item, items_remaining} =
items
|> Enum.filter(&(&1.weight <= weight_limit))
|> pop_biggest_profit()
if is_nil(biggest_item) do
[]
else
weight_remaining = weight_limit - biggest_item.weight
[biggest_item | keep_packing(items_remaining, weight_remaining)]
end
end
A cada passo da recursão, a gente filtra os itens que não cabem mais e separa qual deles é o mais lucrativo. Se não houve nada a ser extraído (tipo se nada sobrou depois da filtragem), então paramos por aqui. Mas caso algo haja um maior, então tal item atual é posto numa lista junto do próximo item. E dado que isso é uma recursão, o próximo item é apenas a repetição desta mesma tomada de decisão, porém com o peso recalculado e a lista já filtrada (e com o item já escolhido excluído dela para não ser pego duas vezes).
Arrisco dizer que esse algoritmo está mais simples do que o fluxograma.
Agora, para fechar as lacunas, usamos uma função “mágica” ali que é pop_biggest_profit que separa o item mais lucrativo dos demais. A implementação dela é esta, recebendo a lista de itens e retornando uma tupla:
defp pop_biggest_profit(items) do
biggest = Enum.max_by(items, & &1.profit)
rest = List.delete(items, biggest)
{biggest, rest}
end
Esta funçãozinha em particular irá sempre até o fim mesmo, pois o item mais lucrativo pode estar tanto no início da lista quanto no final da coleção, assim não vale a pena fazer nenhum loop customizado para otimizar, só confiar no básico da biblioteca tá ok. Assim, é encontrado o maior item biggest baseado na propriedade profit, depois uma versão nova da lista rest excluindo esse item é criada, e por fim uma tupla retornando ambos é criada.
Rodando aqueles testes, está tudo nos conformes:

Tá em um repositório no GitHub caso queira clonar e rodar exatamente o mesmo que eu acima ou ver o código inteiro de uma vez só.
E a complexidade computacional?
É difícil, vamos pensar
De antemão, lembre que o problema em si tem muitas variações e cada variação tem múltiplas formas de implementação. Então só procurar no Google ou perguntar ao Chat GPT provavelmente não é satisfatório — eu tentei e as respostas foram em geral meias-verdades, nunca considerando todas as características e decisões tomadas aqui. Possivelmente por ser em Elixir, isso dificultou a vida das IAs, pois há menos conteúdo para tentarem imitar.
Lendo o código por alto, são observadas várias operações lineares de filtro e mapeamento, aparentemente nunca aninhadas, o que é indício de complexidade linear. Mas temos dois fatores complicadores aqui, a recursão e o fato de não sabemos quais itens vão “sumir” a cada iteração. Cada passo toma suas decisões arbitrárias que impactam na seguinte. Sem olhar pra quantidade de itens, é possível que só um caiba (ou nenhum), assim a repetição para logo no início. Mas também é possível que todos caibam, fazendo o algoritmo tomar uma decisão para cada item.
Complexidade em Big O do Knapsack
Dito isso, arrisco responder que em tempo é linear O(n) no melhor caso, quando a primeira iteração confirma que coube nada ou só um item, não precisando avançar para uma segunda. Mesmo neste caso, a confirmação ocorre após a exploração da lista inteira de itens, pois não sabemos se o mais valioso está no começo ou no fim da coleção, ou sequer quais cabem na mochila. Interessante comentar que, mesmo havendo várias operações lineares, estão todas uma atrás da outra, dando n+n+…+n=c*n, porém o coeficiente c é constante e independente, logo ignorado para a notação Big O.
Ainda me aventurando nesta arte analítica das mentes eruditas, diria que a complexidade é quadrática O(n^2) no pior caso em que todos os itens cabem na mochila. Pois sabendo que cada decisão explora todos os n itens da coleção linearmente, a recursão aninhará isso forçando esse mesmo padrão linear a se repetir n vezes, ou seja, as funções combinadas dão n*n=n^2. Interessante comentar que neste caso, a recursão diminuirá em 1 a quantidade de itens da próxima recursão, assim na primeira vez serão n, na segunda n-1, na terceira n-2, que expressando matematicamente em n+(n-1)+(n-2)…+1 é equivalente à progressão aritmética [(n+1)/2]*n, mas novamente os termos constantes e independentes são ignorados nos trazendo de novo até n*n.
Variação do Knapsack no app da Cumbuca
Uma aplicação disso na vida real foi no aplicativo em que contribuo chamado Cumbuca, que possui uma funcionalidade em que podemos cadastrar um cartão de crédito em (por exemplo) um serviço de streaming, e cada mensalidade deste único cartão vai descontar do dinheiro de várias pessoas ao mesmo tempo. Assim, todo mundo de um certo grupo paga automaticamente.
A princípio, se uma das pessoas não tiver saldo disponível, o pagamento é recusado. Mas isso opcionalmente é flexibilizado, e caso algumas pessoas não possam pagar, as outras irão compensar (e até gerar cobrança para depois). E aí que entra o problema: como flexibilizar o pagamento de forma que cada pessoa pagante contribua o máximo possível dentro de sua disponibilidade de saldo?
Se você analisar ao pé da letra, pode parecer diferente, afinal qual é “a mochila” aí nisso tudo? Acontece que a primeira solução do problema, quando o resolvi, estava idêntica à solução que fizemos acima. Mas… o mundo real é mais caótico.

Dentre as diferenças: há muitas mochilas de origem (saldos disponíveis) e destino (contribuições no pagamento); há pesos em porcentagem (a princípio o rateio é na porcentagem que os usuários definem e essa proporção deve ser refletida ao final das compensações); os dinheiros não são números inteiros porém precisam ser arbitrariamente arredondados com frequência (não faz sentido cobrar 1,00009 de ninguém e nem é possível dividir R$ 0,01 entre duas pessoas); e coisas do tipo.
Mas o raciocínio é quase o mesmo: várias iterações, usar o valor e peso das contribuições sem estourar o saldo, mirar no valor final, e ter o zelo de precisão que toda operação financeira precisa ter. Naturalmente, não posso revelar todos os detalhes do problema e da solução. Mas é só experimentar as funções de cartão da Cumbuca para observar tudo isso em ação. 😉
Um “truque” que deu muito certo foi usar o máximo possível a natureza do NP-completo a nosso favor. Isto é, aceitar que o algoritmo não vai encontrar a resposta perfeita, mas ir fazendo o máximo possível de ajustes finos (via testes unitários) para manter tudo mais previsível. O último pulo do gato é lembrar que pro NP-completo é fácil checar se o resultado está correto, portanto uma ideia interessante é o próprio algoritmo validar seu resultado antes de chamar efeitos colaterais como movimentar dinheiros… quase como o checksum feito pelo HTTP para confirmar se pacotes TCP chegaram íntegros entre pontas.
Mas antes que eu me distraia mais, terminarei a postagem por aqui. Caso essa experiência tenha sido útil pra você ou até se você tem algo a acrescentar/corrigir nas minhas análises, é só me encontrar nas redes sociais. 👋🏼
